In addition to reading this guide, we recommend you run the Elasticsearch Health Check-Up. It will detect issues and improve your Elasticsearch performance by analyzing your shard sizes, threadpools, memory, snapshots, disk watermarks and more.The Elasticsearch Check-Up is free and requires no installation.
In addition to reading about slow indexing in Elasticsearch nodes, its causes, and how to prevent it, we recommend you run the Elasticsearch Health Check-Up. It will detect issues and improve your Elasticsearch performance by analyzing your shard sizes, threadpools, memory, snapshots, disk watermarks and more.
The Elasticsearch Check-Up is free and requires no installation.
Overview
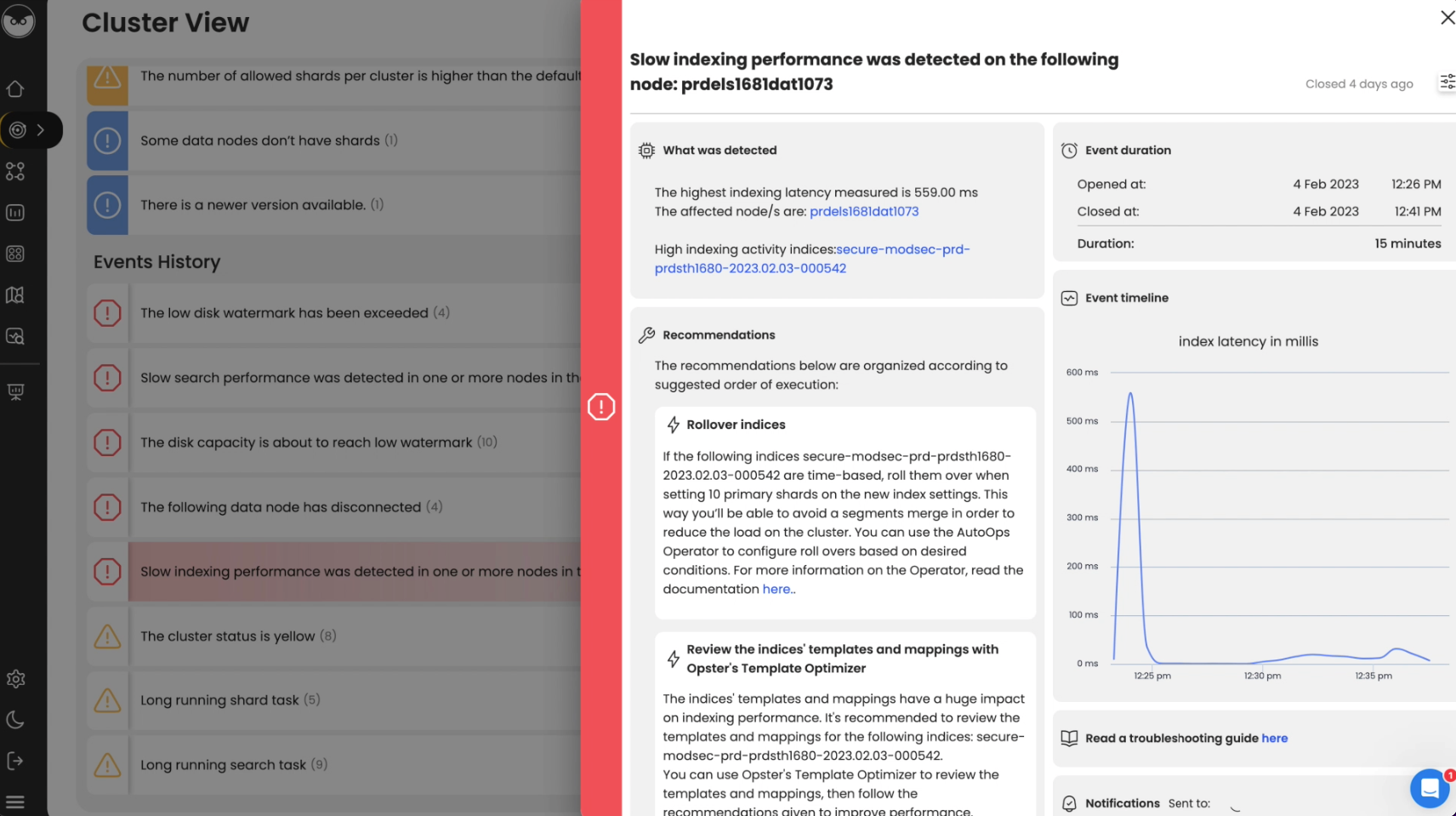
If the indexing queue is high or produces time outs, this indicates that one or more Elasticsearch nodes cannot keep up with the rate of indexing.
Rejected indexing might occur as a result of slow indexing. Elasticsearch will reject indexing requests when the number of queued index requests exceeds the queue size. See the recommendations below to resolve this.
Possible causes
Suboptimal indexing procedure
Apply as many of the indexing tips as you can from the following blog post: Improve Elasticsearch Indexing Speed with These Tips.
Irregular indexing
Try to avoid process architectures that create irregular indexing activity. If possible, use queueing systems to help spread the load over time.
Hot node
If the indexing activity appears to be spread unevenly between the nodes, then the issue is most likely related to the number of shards on the index.
For example, in a logging application, indexing activity is often concentrated on the index for today’s logs. If this index has a small number of shards in relation to the number of data nodes in the cluster, then you can find that the nodes containing the shards of this index are working hard, while others without any shards for the “hot” index are less busy. In this case, it could be useful to increase the number of shards on the index being written to in order to spread this indexing activity across a greater number of nodes.
Exactly how to implement this will depend upon the way the indices are being managed. For example: If the indices are time based, you can simply increase the number of shards in the index template, and wait for the next index to be created.
The use of ILM is also a good solution to this issue, since you can specify the number of shards, and then define a policy so that Elasticsearch rolls over the index and adjusts the number of shards according to a predefined policy. If, on the other hand, the index is not time based, then it may be necessary to create a new index with a higher number of shards and reindex, or change the basis upon which the application manages its indices.
How to prevent slow indexing
To prevent this from happening you can try and optimize the indexing process. Please review this guide: Improve Elasticsearch Indexing Speed with These Tips, which incorporates some valuable short tips on how to optimize the indexing process.
If you have optimized the indexing and sharding process, and your nodes still time out, you can also try and add new data nodes to your cluster, but this may not be a solution that will fix the problem permanently.




